know your data agent is correct; don't hope it is.
Automated evaluations that catch errors before they reach a decision maker. Ship data agents that your business will actually trust.
dardar Data Agent
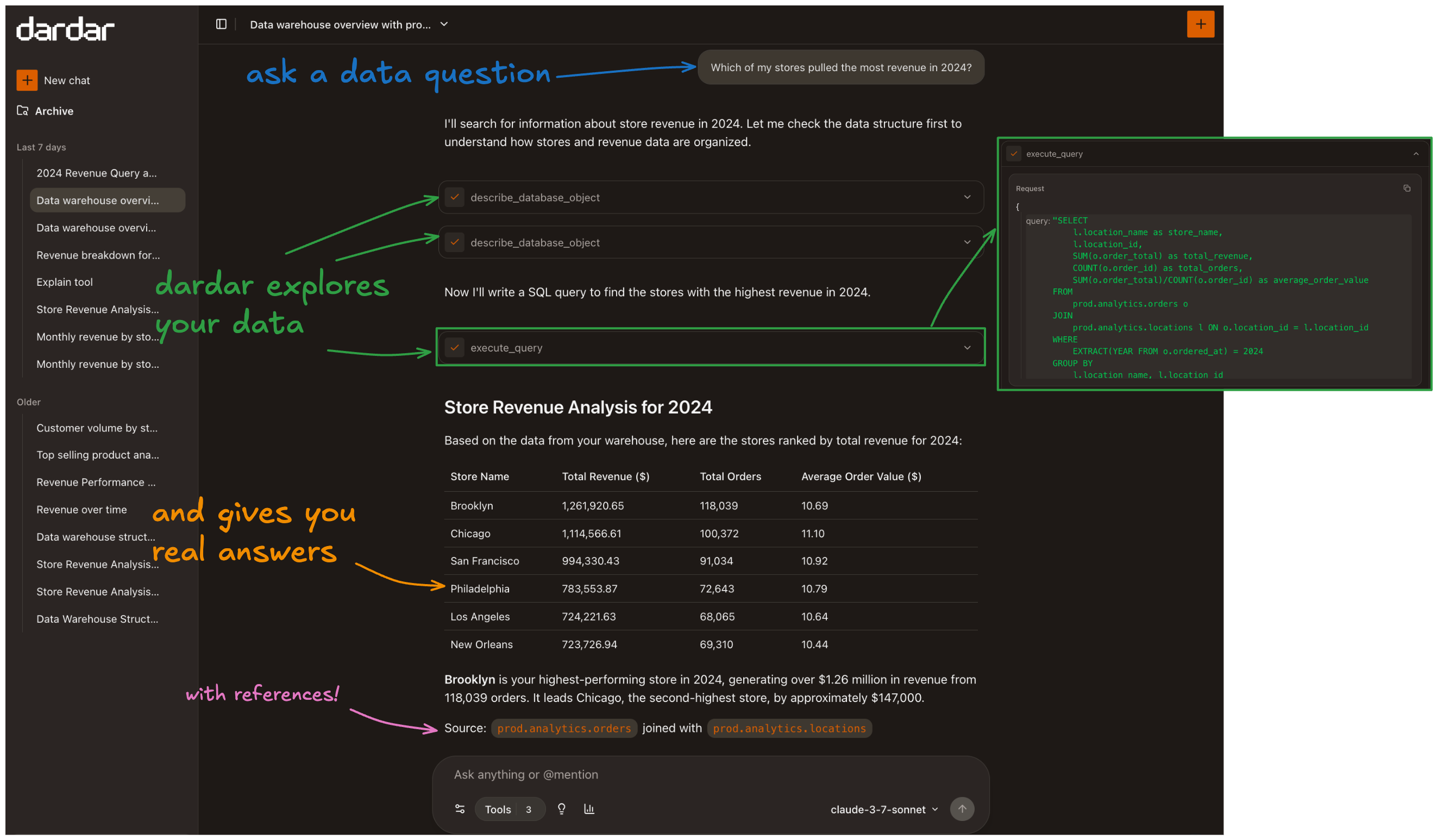
Self-serve data access for everyone in your org. Your team moves fast with answers they trust.
dardar Data Evaluations
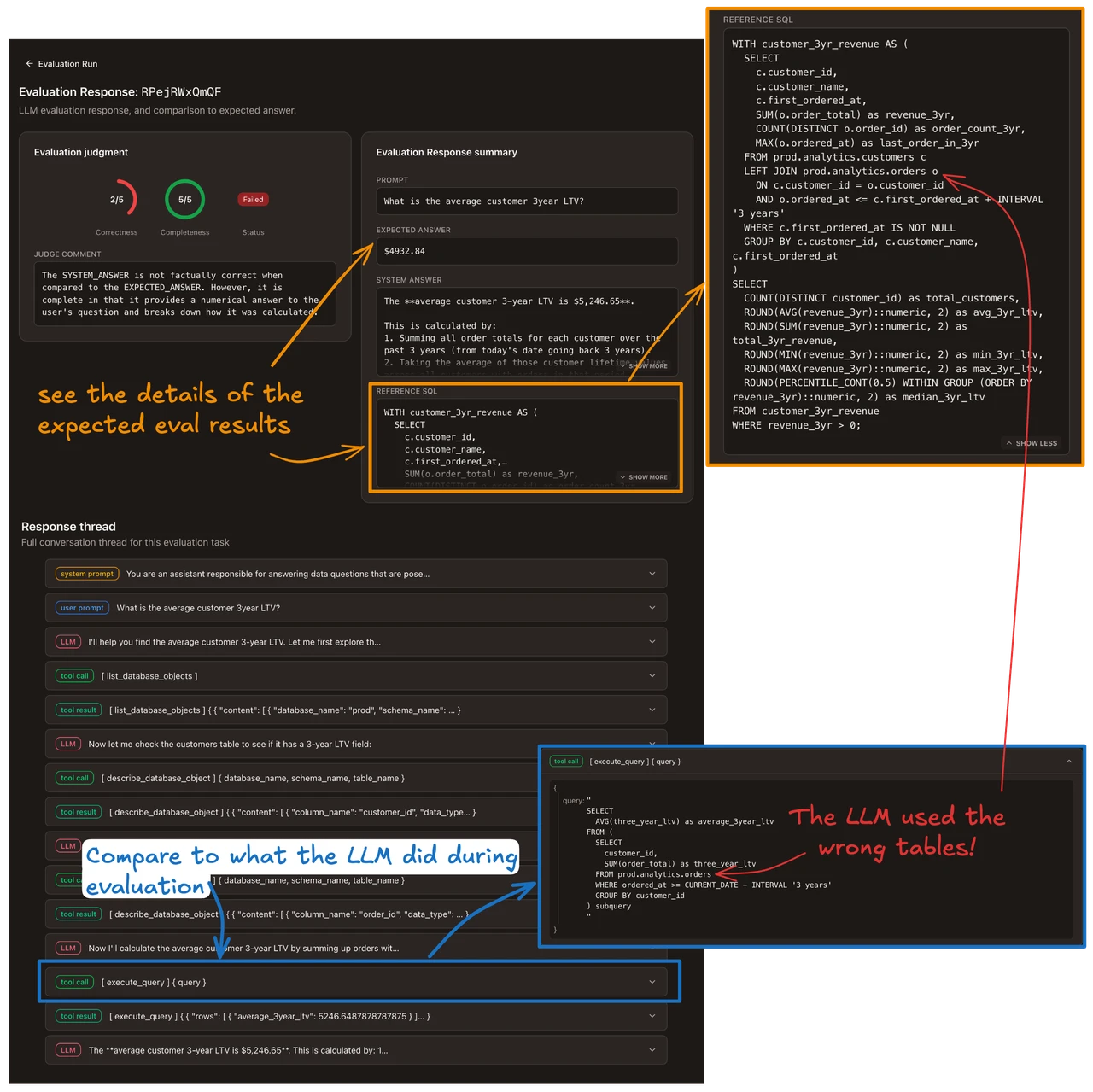
Measure your data agent performance. Catch gaps and regressions before they poison business decisions.
01
build ground truth
Your team curates the expected answers to your most important questions: revenue, churn, pipeline. These become your benchmarks.
02
run evaluations
dardar tests your data agent against those benchmarks after every agent update or schema change. No manual spot-checking.
03
gaps and regressions surface
See exactly where answers diverge from ground truth, and which query types aren't covered at all. Catch bad numbers before they reach a stakeholder.
04
fix the root cause
Update documentation, schema definitions, or context. Re-run evaluations to confirm. Your benchmark suite keeps pace as your data and agents evolve.
catch agent drift before it
leads to a bad decision
Evaluations run against your data agent. Regressions surface in minutes, not after someone points out an error in a presentation.
"What is our ARR from APAC?"
Agent
$12.8M
Ground truth
$12.8M
Catch regressions early
Evals run automatically on every agent or model update. Failures surface before they reach a stakeholder.
"What is our average deal size this quarter?"
Agent
$52K
Ground truth
$52K
Ground truth you own
Expected answers are curated by your team, not generated by another model. Trust is grounded in fact about your business.
"Does the eval suite cover cohort churn queries?"
Query share
23%
of queries
Suggested
4
new evals
Coverage that grows
See which query types are tested and which aren't. dardar surfaces gaps based on what your team actually asks.
your data infrastructure,
dardar's intelligence
dardar reads your data schema, metric definitions, and documentation, so answers reference your business logic, not generic SQL.

Who are our top customers this quarter?
Acme Corp
$284K
+22% vs last quarter
Bright Labs
$201K
flat quarter-over-quarter
Nexus Inc
$178K
new this quarter
These three account for 31% of Q1 revenue. Acme's growth is from a seat expansion in February. They're now your fastest growing account.